En programmation le mode de passage de paramètre pour l'appel d'une fonction (ou d'une méthode) est un point central car il est souvent source de bug. Un paramètre passé à une fonction est avant tout une donnée. Généralement on peut distinguer deux modes de passage:
- Passer la valeur de la donnée: le paramètre local de la fonction va être construit à partir de la recopie des valeurs de la donnée du bloc appelant.
- Passer la référence de la donnée : La variable locale ne contiendra pas les valeurs de la donnée de départ mais la référence (adresse) de la donnée. C'est ce qu'on appelle un pointeur.
Une donnée d'un programme recoupe deux choses: une nom de donnée et un espace de stockage contenant la ou les valeurs associées à ce nom de donnée.
Lorsque qu'on passe un paramètre par valeur, une nouvelle donnée est créée et son espace associé est alimenté par une copie de la donnée émettrice. Dans le cas d'un passage par référence ou par adresse, le nom de donnée est créée et son espace associé est le même que celui de la donnée émettrice. Les deux données pointent vers le même espace mémoire.
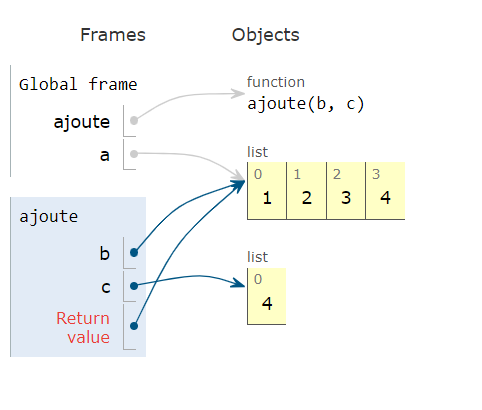
Dans les langages sophistiqués, ce mécanisme est masqué au développeur. Il n'aura pas à se poser la question. Ainsi en Python, c'est l'adresse de la variable qui sera passée comme paramètre à l'appel de la fonction pour les données de type conteneur (list, tuple, set , obj) . C'est le contenu de la variable 'self' d'une méthode Python.
Exemple pour la fonction suivante en Python:
Avec comme exécution:
Et un effet de bord pas toujours voulu, illustré par Pythontutor : les deux variables pointent sur la même zone mémoire.
La même fonction appelée avec un tuple donnera un effet différent:
Explication: l'instruction '+=' n'a pas le même comportement en présence d'objet muable (list) qu' immuable (tuple). C'est pourquoi,
il faut éviter de passer en paramètre des objets muables à une fonction Python.Et en Golang ? .
Le Go permet de choisir son mode de passage de paramètre : par valeur (recopie) ou par pointeur (adresse). Mais il va plus loin que ça. Pour une méthode, il va générer plusieurs signatures: une par valeur et une par pointeur. En fonction de ce que recevra la méthode, la bonne méthode sera appelée.
Exemple si on a codé ceci :
// GetFace: cette fonction/methode retourne le nombre de face du dé.
func (d De) GetFace() int {
return d.Nbface
}
Bien que la signature préfigure une passage par valeur, il sera possible de fournir un pointeur.
Le compilateur aura généré les 2 formes de transmission: par valeur ou par pointeur
d1 := De{6}
fmt.Printf("%v , %T\n", d1, d1)
fmt.Printf("nb de face (adresse):%v\n", d1.GetFace())
fmt.Printf("nb de face (pointeur):%v\n", (&d1).GetFace())
d1p := &d1
fmt.Printf("nb de face (pointeur V2):%v\n", d1p.GetFace())
Avec comme résultat:
{6} , libde.De
nb de face (adresse):6
nb de face (pointeur):6
nb de face (pointeur V2):6 Cette simplification fonctionne dans aussi dans le cas inverse où une fonction doit utiliser un pointeur.
Cette facilité à une contrepartie : des difficultés à comprendre ou à reprendre un code.
Aussi, il est recommandé d'utiliser dans le codage et dans l'exécution le passage par adresse (pointeur)
Car seule l'utilisation des pointeurs permettra de modifier les attributs de la structures.
Comme ci-dessous:
// methode setter
d4 := DePipe{
De{6},
5,
}
fmt.Println("avant appel", d4)
d4.SetFaceValeur(2)
fmt.Println("apres appel", d4)
tmp := &d4
tmp.SetFacePointeur(3)
fmt.Println("apres appel", d4)
(&d4).SetFacePointeur(6)
fmt.Println("apres appel", d4)
Avec comme exécution:
avant appel {{6} 5}
par valeur {{6} 2}
apres appel {{6} 5}
par pointeur {{6} 3}
apres appel {{6} 3}
par pointeur {{6} 6}
apres appel {{6} 6}
Conclusion: utilisez les pointeurs.
source https://github.com/germanlinux/lemongo/tree/main/lemonlabs/src/pointeurs


































{kind=link}